I belong to : Collection
https://segmentfault.com/a/1190000011635556?utm_source=tag-newest
可以把https拆成tcp/tls/http这三层来看,tcp handshake >> TLS(SSL) handshake >> http request/response
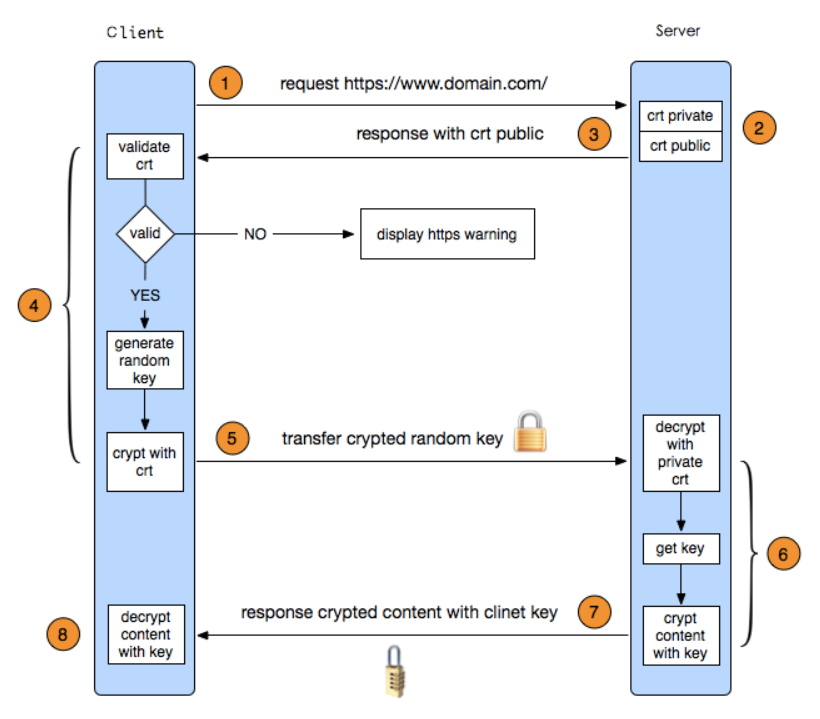
https://blog.csdn.net/u012361288/article/details/54883154
http://www.cnblogs.com/lovesong/p/5186200.html
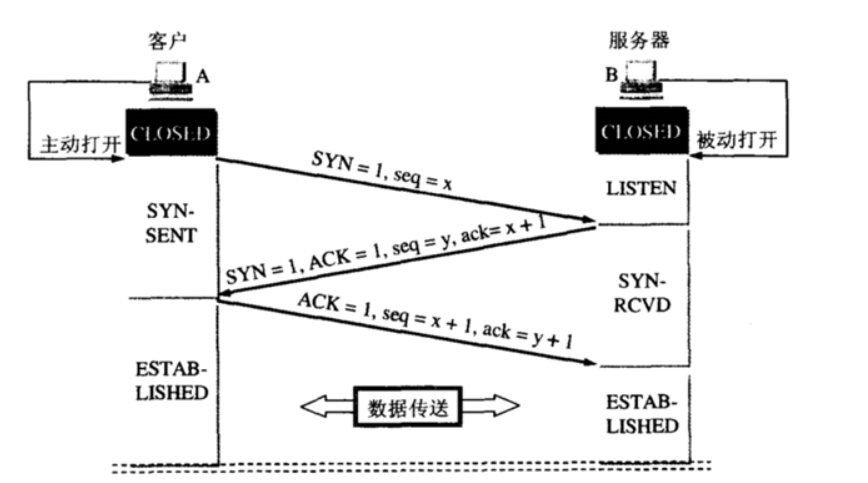
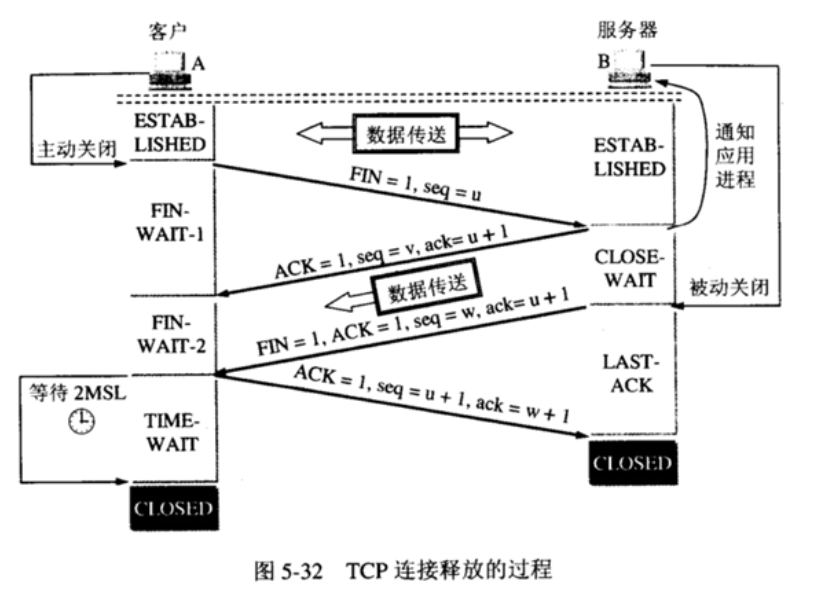
1、TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接。
2、TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付。
3、TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文的。UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等)。
4、每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信。
5、TCP首部开销20字节;UDP的首部开销小,只有8个字节。
6、TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道。
在长连接的基础上,将客户端的其他请求都交给这一个连接去处理。这里服务器需要注意一件事情。那就是这个请求的先后顺序是不能颠倒的
在使用持久连接的情况下,某个连接消息的传递类似于
请求1 -> 响应1 -> 请求2 -> 响应2
管线化:某个连接上的消息变成了类似这样
请求1 -> 请求2 -> 请求3 -> 响应1 -> 响应2 -> 响应3
只有GET和HEAD要求可以进行管线化,而POST则有所限制
初次创建连接时也不应启动管线机制,因为对方(服务器)不一定支持HTTP/1.1版本的协议。
HTTP1.1要求服务器端支持管线化,但并不要求服务器端也对响应进行管线化处理,只是要求对于管线化的请求不失败,而且现在很多服务器端和代理程序对管线化的支持并不好,现代浏览器Chrome和Firefox默认并未开启管线化支持
浏览器对于同一域名下允许的并发请求数作了限制

域名发散就是为了突破浏览器对于同一域名并发请求数的限制
域名收敛就是将静态资源放在一个域名下不进行发散,这主要是为了适应移动端的发展需求;通常DNS是一个开销较大的操作,而移动端由于网络带宽和实时性、资源等的限制,这些开销对移动端的用户体验是致命的,因此需要进行域名收敛;
四大内核分别是:Trident(也称IE内核)、webkit、Blink、Gecko。
五大浏览器采用的都是单内核,而随着浏览器的发展现在也出现了双内核。像360浏览器、QQ浏览器都是采用双内核。
loader 用于加载某些资源文件。 因为webpack 本身只能打包commonjs规范的js文件,对于其他资源例如 css,图片,或者其他的语法集,比如 jsx, coffee,是没有办法加载的。 这就需要对应的loader将资源转化,加载进来。从字面意思也能看出,loader是用于加载的,它作用于一个个文件上。
plugin 用于扩展webpack的功能。它直接作用于 webpack,扩展了它的功能。当然loader也时变相的扩展了 webpack ,但是它只专注于转化文件(transform)这一个领域。而plugin的功能更加的丰富,而不仅局限于资源的加载
https://segmentfault.com/a/1190000011081338
AMD CMD ,这两个东西是一种规范,他们实际产物是 AMD是RequireJS,CMD的产物是seajs,他们的出现都是在COMMONjs基础上发展而来的。
AMD偏向于依赖前置,CMD偏向于用到时才运行的思路,从而导致了依赖项的加载和运行时间点会不同
与CommonJS用require()方法加载模块不同,在ES6中,import命令可以具体指定加载模块中用export命令暴露的接口(不指定具体的接口,默认加载export default),没有指定的是不会加载的,因此会在编译时就完成模块的加载,这种加载方式称为编译时加载或者静态加载。 而CommonJS的require()方法是在运行时才加载的
对AMD,CMD,CommonJS有没有了解? 为什么要模块化?不用的时候和用RequireJs的时候代码大概怎么写? 说说有哪些模块化的库,有了解过模块化的发展的历史吗? 分别说说同步和异步模块化的应用场景,说下AMD异步模块化实现的原理? 如何将项目里面的所有的require的模块语法换成import的ES6的语法? 使用模块化加载时,模块加载的顺序是怎样的,如果不知道,根据已有的知识,你觉得顺序应该是怎么样的?
仅在同级的vnode间做diff (一)优先处理特殊场景
(1)oldstart和newstart同类型 \ oldend和newend同类型:不用移动它们对应的DOM
(2)oldStart和newEnd,以及oldEnd和newStart指向同类节点的: 直接移动DOM就好
(二)、“原地复用”
Vue在判断更新前后指针是否指向同一个节点,其实不要求它们真实引用同一个DOM节点,实际上它仅判断指向的是否是同类节点(比如2个不同的div,在DOM上它们是不一样的,但是它们属于同类节点),如果是同类节点,那么Vue会直接复用DOM,这样的好处是不需要移动DOM。
https://blog.csdn.net/m6i37jk/article/details/78140159#commentBox
http://www.yyyweb.com/4707.html
配置超长时间的本地缓存 —— 节省带宽,提高性能
采用内容摘要作为缓存更新依据 —— 精确的缓存控制
静态资源CDN部署 —— 优化网络请求
更资源发布路径实现非覆盖式发布 —— 平滑升级